Experiment Analysis
Analysis Outline
Explain your approach to data transformation, integration, and management.
Detail how you use the data gathered to isolate millibottlenecks and diagnose their root cause.
Describe the steps needed to analyze your experiment:
-
Copy the tarball archive containing the experiment data to a location proximate to the cloned Elba Github repository.
-
Unzip the copied archive.
-
Navigate to the parsers directory of the cloned Elba Github repository.
-
Execute “runparsers.sh” by providing the following:
-
Path to the directory containing the unzipped archive
-
Target location to store the processing results
-
milliScope Data Flow and Architecture
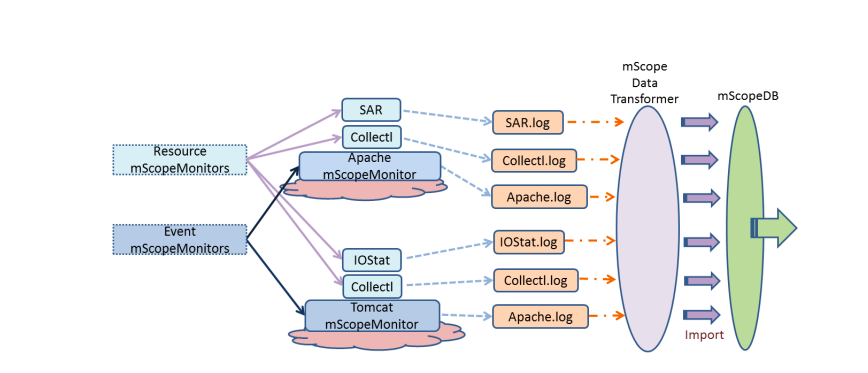
The data transformation flow of milliScope. The event mScopeMonitors capture timestamps, as shown in Figure 4, in the component logs, while the resource mScopeMonitors record the system resource utilization. mScopeDataTranformer converts these unstructured data to structured tuples and loads them into a dynamic data warehouse, mScopeDB, for advanced analysis.
milliAnalyst
milliAnalyst is a uniform data interface consisting of three entities:
-
PointinTime
-
DownstreamServiceTime (DST)
-
ResourceObservations
Each of these entities can have a variable number of number of attributes. The number of nodes specified in the experiment determines the number of DST attributes. Also note that the number of attributes can also depend on characteristics that might not be known prior to running an experiment, such as a node’s number of CPUs, cores, NICs or disks.
The method needs to handle this variable number of attributes, i.e. there are no fixed schemas. The method also needs to be able to integrate data across time and space.
The representation needs to be able to handle data anomalies and support efficient filtering and retrieval of small data subsets across all of the measurements and support graph-based reasoning.
milliBottlenecks
Millibottlenecks happen in different system layers
-
System software: Java garbage collection
-
Processor architecture: DVFS
-
Application Virtual Machine consolidation
Though short-lived, millibottlenecks have big impact on n-tier application performance
-
VLRT requests
-
Queue amplification from n-tier system component dependencies
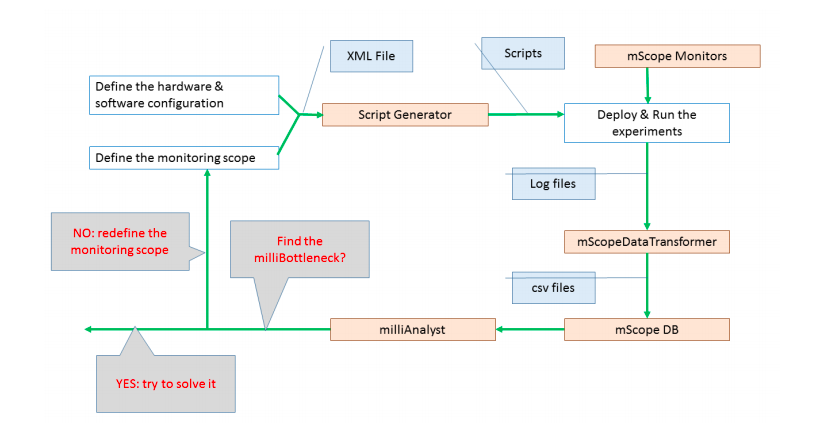
Above is the work flow of milliBottleneck discovery. Users define the configuration file at first, and the script generator generates scripts which set up the experiment environment and deploy milliScope as well as other softwares. mScopeDataTransformer converts these unstructured data to structured tuples in mScopeDB as described in Figure 3 for advanced analysis.
Solutions
Three kinds of solutions for Latency Long Tail Problem
-
Bug-fix, specific solutions for each cause (many causes, not all can be fixed)
-
General solutions for transient bottlenecks (primarily improved queue management)
-
Last-resort solution
Bug-Fix for Specific Solutions
-
Some cases can be “fixed”
-
Java GC in JVM 1.5 was “fixed” in JVM 1.6
-
DVFS anti-synchrony can be “fixed” by changing control periods (some complications)
-
-
Other cases are harder to fix
- VM consolidation case (noisy neighbor) is really non-deterministic
-
Kernel daemon processes (many)
General Solutions
-
Approaches that address transient bottlenecks (instead of specific “bugs”)
- 3 stages: (1) transient bottleneck formation, (2) queue amplification, (3) packet retransmission
-
(1) Transient bottleneck detection and remedial action (e.g., disruption)
- Difficult, due to the short lifespan of transient bottlenecks